
Salientprocess acquisition by IBM will make SPARK toolkit core part of IBM BPM in future release. SPARK introduces some nice new concepts, one of it is addressing that keeps SPARK containers invisible. Its public API promises to make your own coach view a container and I needed it on my code. So I tried and it did not work. Few hours of experiments with debugging SPARK code led me to workaround and defect report.
SPARK UI toolkit is built on top of IBM BPM coach framework and tries to hide some of its quirks. One of it is addressing: in coach framework navigation thru hierarchy of objects requires walking thru each level using context.getSubview() multiple times. Such boilerplate code breaks easily on layout reogranization. SPARK addressing copes with both problems allowing path-like navigation and by distinguishing views from containers (like layouts) making the latter non-addressable.
Let see it by example. Imagine we have own widget identified by “Block” that has content box filled by vertical layout “Vertical”, and inside layout there is text field with “Text” view id.
// classic navigation var block = this.context.getSubview("Block")[0]; var vert = block.context.getSubview("Vertical")[0]; var text = vert.context.getSubview("Text")[0]; // spark navigation (note layout skipped in address!) var text = bpmext.ui.getView("/Block/Text"); |
Now, what happen if we add extra horizontal layout between vertical and text?
// classic navigation - must be modified var block = this.context.getSubview("Block")[0]; var vert = block.context.getSubview("Vertical")[0]; var horiz = vert.context.getSubview("Horizontal")[0]; var text = vert.context.getSubview("Text")[0]; // spark navigation - simply left intact! var text = bpmext.ui.getView("/Block/Text"); |
What is even more attracting is that “Block” could be also invisble in addressing if its plays container role. This way with or without block we could simply address text by getView("Text")! And SPARK UI documentation clearly says that bpmext.ui.loadContainer() called on load handler of coach view serves this purpose.
Testing containers
Test layout
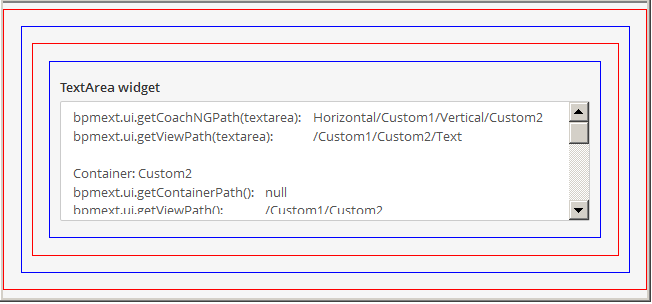
Let start with regular coach view called “Custom Container CV” that has content box inside to place other coach views. To test behavior I made up a human service with coach holding four levels deep hierarchy mixing layouts (marked by red border) and my contaiers (blue borders). On the bottom there is text area that reports its own path plus collects path reports on all four containers.
Initially paths were reported as follows:
bpmext.ui.getCoachNGViewPath(textarea): Horizontal/Custom1/Vertical/Custom2 bpmext.ui.getViewPath(textarea): /Custom1/Custom2/Text Container: Custom2 bpmext.ui.getContainerPath(): null bpmext.ui.getViewPath(): /Custom1/Custom2 Container: Custom1 bpmext.ui.getContainerPath(): /Custom1 /* null expected, a SPARK bug? */ bpmext.ui.getViewPath(): /Custom1 Container: Vertical bpmext.ui.getContainerPath(): /Custom1/Vertical bpmext.ui.getViewPath(): null Container: Horizontal bpmext.ui.getContainerPath(): /Horizontal bpmext.ui.getViewPath(): null |
What you can read from it is that we have four coach views (getCoachNGViewPath), first horizontal layer then our custom view, then vertical layout, another custom view, and text area at the end.
Note that regular view path (getViewPath) run on text area widget does not “see” SPARK layouts. Also note that view path for containers is null. For container path it is
a bit more irregular as only leaf (deepest) container is always available e.g. for “Vertical” container the path is /Custom1/Vertical missing "Horizontal" at the beginning.
When "Custom container CV" is turned into SPARK container paths are reported this way:
bpmext.ui.getCoachNGViewPath(textarea): Horizontal/Custom1/Vertical/Custom2 bpmext.ui.getViewPath(textarea): /Text Container: Custom2 bpmext.ui.getContainerPath(): /Custom2 bpmext.ui.getViewPath(): null Container: Custom1 bpmext.ui.getContainerPath(): /Custom1 bpmext.ui.getViewPath(): null Container: Vertical bpmext.ui.getContainerPath(): /Vertical bpmext.ui.getViewPath(): null Container: Horizontal bpmext.ui.getContainerPath(): /Horizontal bpmext.ui.getViewPath(): null |
Now it is clear that all wrappers around text area are transparent. Address path is direct, just a /Text and all cointainers have null view paths. Interestingly container paths are dangling at root (because parent containers are still invisible even for container path?) even though "Vertical" /Horizontal/Vertical path would be more natural then just /Vertical. Fortunately container paths are less relevant in business logic.
Setting coach view SPARK container
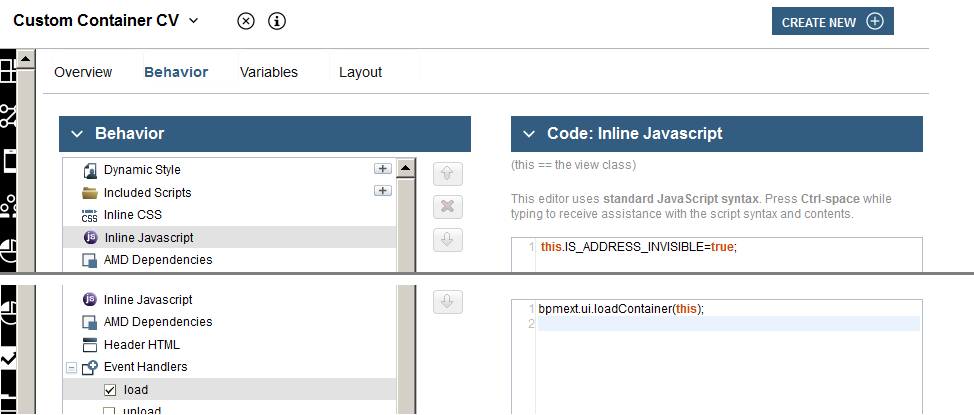
SPARK 4.4.4 documentation only mentions container creation through bpmext.ui.loadContainer(). Placed this method in coach load lifecycle handler made coach view addressable as container (bpmext.ui.getContainer() and bpmext.ui.getContainerPath() methods).
My coach view was still wronlgy available as regular view (view bpmext.ui.getView() and bpmext.ui.getViewPath() methods). It took me long time inspecting SPARK layouts code to understand SPARK public API shortcomings and make my coach view working as container -- I shared my concerns on product forum and SPARK support team confirmed my findings.
As of today the only way to make coach view true SPARK container is twofolds:
- set coach views property
IS_ADDRESS_INVISIBLEto true before content box is managed (i.e. in inline javascript); this way coach view is not registered as regular view - register coach view as container calling
bpmext.ui.loadContainer()during load phase.
Cointaner in view-level handlers
Choosing prototype-level handlers
Container in prototype-level handlers
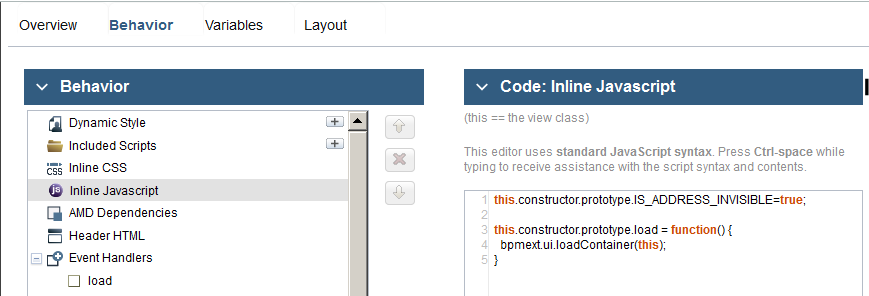
If coach view uses prototype-level handlers (see documentation why), then the whole container initialization code can be placed in inline JavaScript. For better debugging support code can be placed in separate JavaScript file same as SPARK and IBM stock controls are organized.
I hope that SPARK team will fix its API in one of next releases, I will keep you posted.
2016-12-21 update: as of SPARK toolkit version 4.4.5 and 4.4.6 this issue still remains not fixed.




Hi Andy – Someone on my team at Salient referred me to your website. I am glad you are enjoying working with the SPARK UI toolkit.
Regarding addressing and containers, we took the approach that, while some container views might only exist for cosmetic reason, other containers may not. For example a Well control provides only visual candy and therefore we never count it in the addressing of the child controls it contains. As you stated, this allows one to move controls in and out of a Well without potentially breaking code that refers to those child controls – which is extremely useful.
But a Table (which is also a type of container) doesn’t exist for cosmetic reasons – meaning a Text control is in a Table not because it looks nicer but because it actually represents repeating data. In that case you must use the Table’s view id in the addressing path of the Text control it contains.
So as a rule, if it’s a cosmetic-only container, then the containers view id is needed in the addressing of its child controls, and if not, then it’s not needed. Now for the fun part…
Layout controls (horizontal and vertical) can be used for cosmetic reasons and/or to display repeating data. Because of this, when a layout control is bound to repeating data, it becomes addressing-relevant (like a table). And if it’s not bound to repeating data, then it’s addressing invisible (like a Well).
Lastly, to create your own container Coach View, you do actually need to use both the IS_ADDRESS_INVISIBLE flag *and* loadContainer() – that’s again because not all containers are necessarily and generically address-invisible, so just using loadContainer isn’t enough because it alone can’t unambiguously convey the intent of the addressing behavior at runtime. All of this is working as designed.
I hope this makes sense to you. It certainly does to us 🙂
–Eric D
Oops – typo: “…as a rule, if it’s NOT a cosmetic-only container, then the container’s view id is needed in the addressing of its child controls, and if it is cosmetic-only, then it’s not needed.”
–Eric
Eric, welcome to my humble blog. It is a pleasure to get detailed explanation from prominent Spark persona.
I fully understand and agree with your perspective. The main reason I shared my thoughts extensively thru Spark/Salient forum and here is that Spark toolkit still have blank spots in knowledge transfer (docs/guides/etc), one of it was container concepts, so I filled the gap on my own :]
I do understand also that you are undergoing great effort being “blue washed” by IBM and I simply hope Spark will only gets better over time. Two thumbs up to Spark team.
-andy.